Our network is full of stories, impact and qualitative data. Colleagues and community members discover and use these narratives daily across a broad range — from communications and social media, to metrics and evaluation, to grant-writing, curriculum case studies, and grist for new outlets like the State of the Web.
Our challenge is: how do we capture and analyze these stories and qualitative data in a more systematic and rigorous way?
Can we design a unified “Story Engine” that serves multiple customers and use cases simultaneously — in ways that knit together much of our existing work? That’s the challenge we undertook in our first “Story Engine 0.1” sprint: document the goals, interview colleagues, a develop personae. Then design a process, ship a baby prototype, and test it out using some real data.

Designing a network story Engine
Here’s what we shipped in our first 3-day sprint:
- A prototype web site. With a “file a story tip” intake process.
- A draft business plan / workflow
- A successful test around turning network survey data into story leads
- Some early pattern-matching / ways to code and tag evidence narratives
- Documented our key learnings and next steps

1) A prototype web site
http://mzl.la/story is now a thing! It packages what we’ve done so far. Plus a work-bench for ongoing work. It includes:
- “File a story” tip sheet — A quick, easy intake form for filing potential story leads to follow up on. Goal: make it fast and easy for anyone to file the “minimum viable info” we’d need to then triage and follow up. http://mzl.la/tip
- See stories — See story tips submitted via the tip sheet. (Requires password for now, as it contains member emails.) Just a spreadsheet at this point — it will eventually become a Git Hub repo for easier tasking, routing and follow-up. And maybe: a “story garden” with a prettier, more usable interface for humans to browse through and see the people and stories inside our network. http://mzl.la/leads
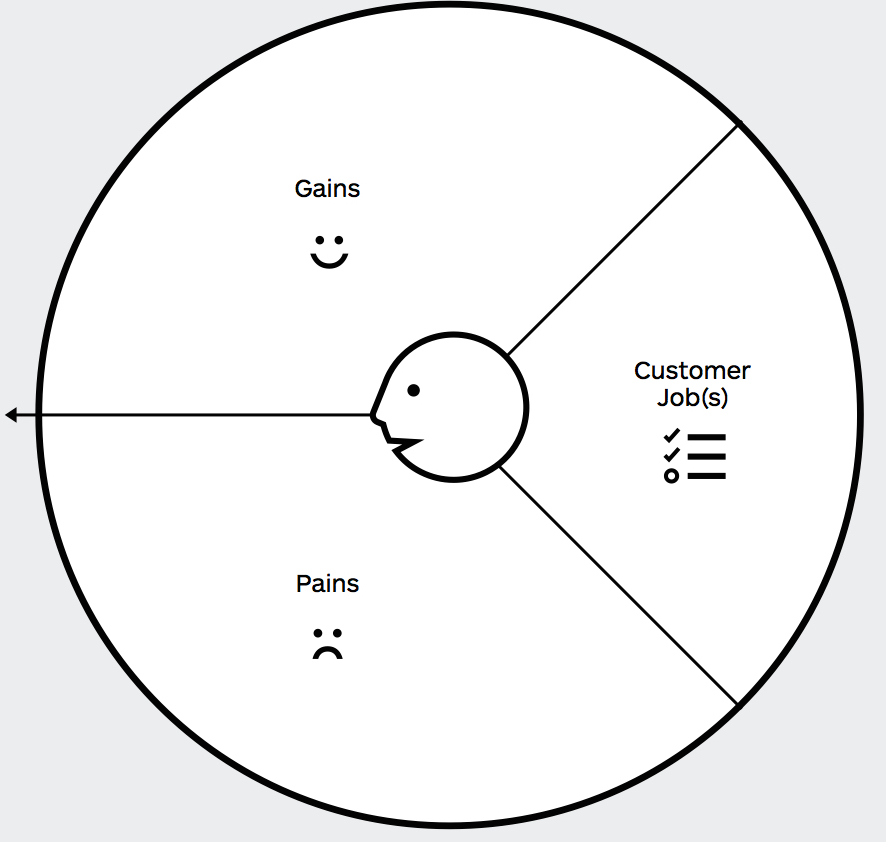
- Personas — Who does this work need to serve? Who are the humans at the center of the design? We interviewed colleagues and documented their context, jobs, pains, and gains. Plus the claims they’d want to make and how they might use our findings. Focused on generating quick wins for the Mozilla Foundation grants, State of the Web, communications and metrics teams. http://mzl.la/customers
- About — Outlining our general thinking, approach and potential methodologies. http://mzl.la/about
- How-To Guides — (Coming soon.) Will eventually become: interview templates, guidance and training on how to conduct effective interviews, our methodology, and coding structure.

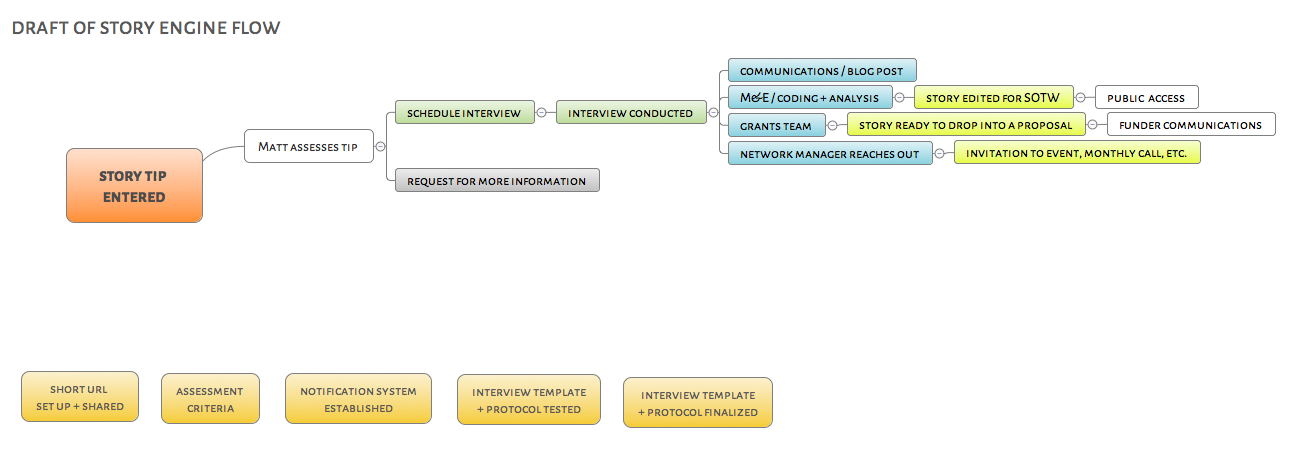
2) A draft business process / workflow
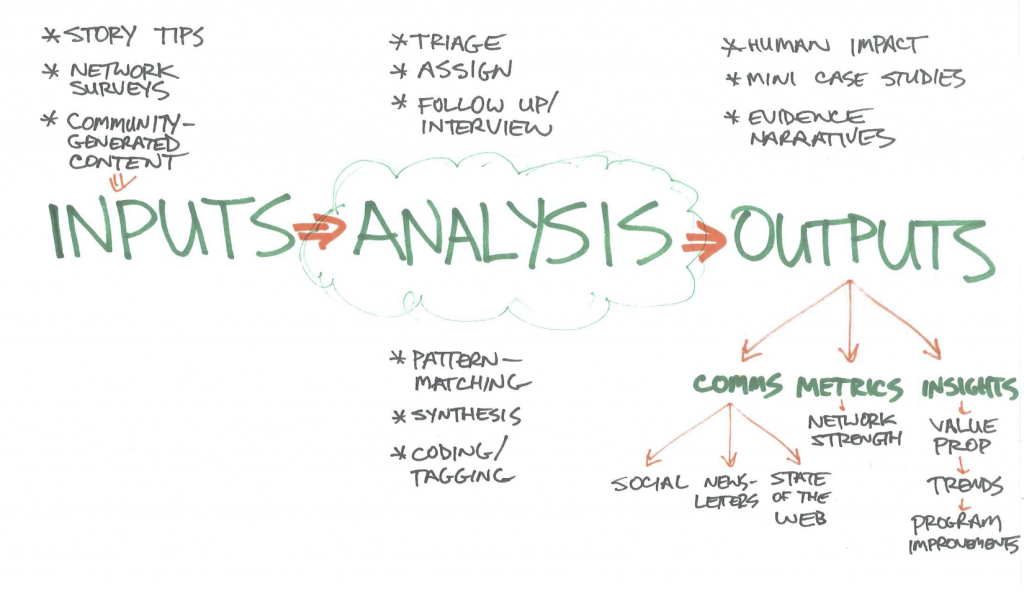
What happens when a story tip gets filed? Who does what? Where are the decision points? We mapped some of this initial process, including things like: assess the lead, notify the right staff, conduct follow-up interviews, generate writing/ artefacts, share via social, code and analyze the story, then package and use findings.
3) Turning network survey data into stories
Our colleagues in the “Insights and Impact” team recently conducted their first survey of the network. These survey responses are rich in potential stories, evidence narratives, and qualitative data that can help test and refine our value proposition.
We tested the first piece of our baby story engine by pulling from the network survey and mapping data we just gathered.
This proved to be rich. It proved that our network surveys are not only great ways to gather quantitative data and map network relationships — they also provide rich leads for our grants / comms / M&E / strategy teams to follow up on.
Sample story leads
(Anonymous for privacy reasons):
- “The network helps us form connections to small organizations that offer digital media and learning programs. We learn from their practices and are able to share them out to our broader network of over 1600 Afterschool providers in NYC. It also expands our staff capacity to teach Digital Media and Learning activities.”
- “My passion is youth advocacy and fighting in solidarity with them in their corner. Being part of the network helps me do more with them like working with libraries in the UK to develop ‘Open source library days; lead by our youths who have so much to share with us all.”
- “The collaboration has allowed the local community to learn about the Internet and be able to contribute to it. The greatest joy is seeing young community girls being a part of this revolution through clubs. Through the process of learning they also meet local girls who share the same passion as they do.”
These are examples of leads that may be worth following up on to help flesh out theory of change, analyze trends, and tell a story about impact. Some of the leads we gathered also include critique or ways we need to do better — combined with explicit offers to help.
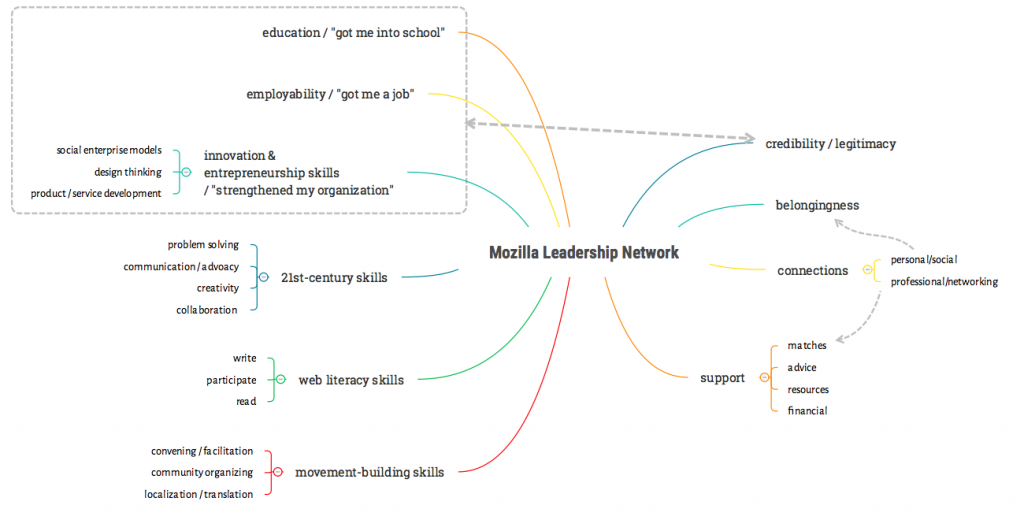
4) Early Pattern-matching / coding AND tagging
One of our goals is to combine the power of both qualitative and quantitative data. Out of this can come tagging and codes around the benefit / value the network is providing to members. Some early patterns in the benefits network members are reporting:
- Support — advice, links to resources, financial support, partners (“matchmaking”)
- Connections — professional, social
- Credibility / legitimacy of being associated with Mozilla
- Belongingness — being part of a group and drawing strength from that
- Skills / practises / knowhow
- Employability / “Helped me get a job”
- Educational opportunity / “Helped me get into school”
- Entrepreneurship & innovation / developing new models, products, services
Imagine these as simple tags we could apply to story tickets in a repo. This will help colleagues sift, sort and follow up on specific evidence narratives that matter to them. Plus allow us to spot patterns, develop claims, and test assumptions over time.
5) Key Learnings
Some of our “a ha!” moments from this first sprint:
- Increased empathy and understanding is key. Increasing our empathy and understanding of network members is a key goal for this work.
This is a key muscle we want to strengthen in MoFo’s culture and systems: the ability to empathize with our members’ aspirations, challenges and benefits.
Regularly exposing staff and community to these stories from our network can ground our strategy, boost motivation, aid our change management process, and regularly spark “a ha” moments.
- We are rich in qualitative data. We sometimes fall into a trap of assuming that what we observe, hear about and help facilitate is too ephemeral and anecdotal to be useful. In reality, it’s a rich source of data that needs to be systematically aggregated, analyzed, and fed back to teams and partners. Working on processes and frameworks to improve that was illuminating in terms of the quality of what we already have.
- The network mapping survey is already full of great stories. Our early review and testing proved this thesis — there’s greater fodder for evidence narratives / human impact in that data.
- Connect the dots between existing work. This “story engine” work is not about creating another standalone initiative; the opportunity is to provide some process and connective tissue to good work that is already ongoing.
- We can start to see patterns emerging. In terms of: the value members are seeing in the network. We can turn these into a recurring set of themes / tags / codes that can inform our research and feedback loops.
Feedback on the network survey process:
Open-ended questions like: “what’s the value or benefit you get from the network” generate great material.
- This survey question was a rich vein. (Mozilla Science Lab did not ask this open-ended question about value, which meant we lost an opportunity to gather great stories there — we can’t get story tips when people are selecting from a list of benefits.)
- Criticism / suggestions for improvement are great. We’re logging people who will likely also have good critiques, not just ra-ra success stories. And (importantly) some of these critiques come with explicit offers to help.
- Consider adding an open-ended “link or artefact field” to the survey next time. e.g., “Got a link to something cool that you made or documented as part of your interaction with the network?” This could be blog posts, videos, tweets, etc. These can generate easy wins and rich media.
What’s next?
We’ve documented our next steps here. Over the last three days, we’ve dug into how to better capture the impact of what we do. We’ve launched the first discovery phase of a design thinking process centred around: “How might we create stories that are also data?”
We’re listening, reviewing existing thinking, digging into people’s needs and context — asking “what if?” Based on the Mozilla Foundation strategy, we’ve created personas, thought about claims they might want to make, pulled from the results of a first round of surveys on network impacts (New York Hive, Open Science Lab, Mozilla Clubs), and created a prototype workflow and tip sheet. Next up: more digging, listening, and prototyping.
What would you focus on next?
If we consider what we’ve done above as version 0.1, what would you prioritize or focus on for version 0.2? Let us know!